Building a new campus affords the opportunity to develop innovative ways to tackle some of the most pressing issues in higher education: learning versus teaching, cost, retention, and graduation. A mandate to address these issues also comes through the accreditation process. Post-secondary educational institutions in the North Central Region of the United States, which includes Minnesota, are accredited by the Higher Learning Commission (HLC). Over the past several years, the HLC revised its criteria for accreditation. The new criteria were adopted by their Board of Trustees in February of 2012 [2]. The new criteria reflect the ongoing shift in accreditation from teaching to learning. As one of its criteria for accreditation, it states that “[t]he institution demonstrates responsibility for the quality of its educational programs, learning environments, and support services, and it evaluates their effectiveness for student learning through processes designed to promote continuous improvement.”[2] To fulfill this criterion, an institution must not only clearly state its goals for student learning and have “effective processes for assessment of student learning and achievement of learning goals,”[2] but also “demonstrate[…] a commitment to educational improvement through ongoing attention to retention, persistence, and completion rates in its degree and certificate programs.”[2] Specifically, an institution is asked to “collect and analyze information on student retention, persistence, and completion of its programs,” [2] and “use information on student retention, persistence, and completion of programs to make improvements as warranted by the data.” [2]
For many years, studies across institutions have tried to identify factors that explain retention and attainment. For instance, a study [3] by Cowart in 1987 focused on improvements in academic advising, orientation programs, and early warning systems. More than 15 years later, freshman seminars, tutoring programs, and advising with selected student populations were added to this list (Habley and McClanahan, 2004) [4]. Many institutions have implemented these and other strategies to help students succeed on their campuses. A more recent survey [5] of public 4-year colleges and universities identified additional factors as the most important in student retention: level of student preparation for college-level work, adequacy of personal financial resources, and student study skills. Despite the large body of research and significant efforts at institutions, the 6-year graduation rate across the nation has hardly changed over the past decade, hovering barely above 55% for bachelor’s students (Figure 1).
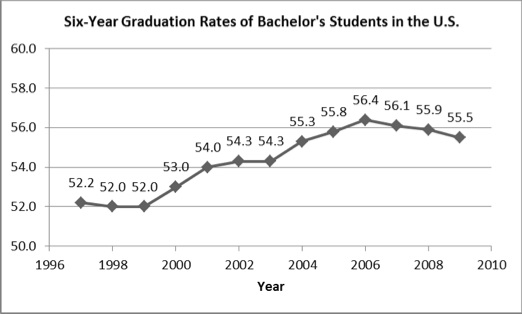
Figure 1: Six-Year Graduation Rates for Bachelor’s Students in the U.S. (Source: The National Center for Higher Education Management Systems)
Despite the overall lack of significant improvements, some institutions have seen substantial increases in retention and graduation rates. For instance, at the University of Minnesota Twin Cities, the 6-year graduation rate increased from 61.4% in 2005 to 70.4% in 2010. Different factors are thought to have contributed to these gains. The traditional approach to identifying the importance of each factor relies on sound statistical theory, namely multivariate statistical methods that reveal combinations of factors together with the percentage of variability in retention or graduation across a population of students that is explained by these factors. The variables that are included in these studies are based on educational theory and availability of data across the population of study.
Borrowing from Biomedical Research
The types of studies mentioned above are similar to epidemiological studies, which have been and continue to be a staple of medical research. However, with the advent of genomics data, different methodologies needed to be developed to analyze the new types of data. The new methods, collectively known as data mining, extract patterns and correlations from very large data sets. The field of research that advances these methods is called bioinformatics. A consequence of the new methodologies is that they allow us to cluster patients into subgroups with defined characteristics. This opens the possibility of individualized medicine where treatments are tailored to clusters of patients. We can translate this individualized approach from medicine to education.
This relationship between individualized medicine and individualized education became clear to me during a talk on gene expression data in the Biomedical Informatics and Computational Biology Journal Club that I was running in Fall 2007. A few weeks before attending this talk, I had a discussion with Chancellor Lehmkuhle on how to measure student success. He mentioned to me that he would like to have the analog of a medical record for students in our program. When I was sitting in the talk and looking at the heat map of gene expression data, I instead saw the “medical records” of our future students. The pieces fell into place: If we collected detailed data on student learning, we could develop individualized education with a vision that is similar to individualized medicine where prevention, diagnosis, and treatment are tailored to patients. In essence, the tools we use in bioinformatics to extract knowledge out of genomics data could be useful in education where we have become similarly data-rich.
Technology is the key to collecting detailed student data across the curriculum. To implement this we would need a database that collects longitudinal data on student learning. The database would contain learning objects, such as quiz questions, homework problems, reading materials, etc. They would be tagged to be searchable. Learning objects would be combined to form modules, which in turn would be combined and delivered as a credit-bearing course. Over time, the curriculum would be represented by a network of modules, each with its own learning objectives and concepts. As students interacted with the curriculum through a curriculum delivery system that is linked to the database, a rich dataset would emerge that could be mined for multiple purposes. The design of the database was funded through a Howard Hughes Medical Institute professor grant that I had received in 2006. We named the database iSEAL: intelligent system for education, assessment, and learning. Initially, iSEAL was a research project. It is now an enterprise-level project that lives in UMR’s IT unit and has been in use in the curriculum at UMR for the last three years. iSEAL is described in this issue in an article by Dick at al. [6].
The data in iSEAL are the basis of the research of faculty at UMR, which tests the efficacy of pedagogical interventions just as clinical trials test the efficacy of new diagnostic tools or treatments. To test the effectiveness of interventions at a much larger scale, we need to identify variables that are readily available to administrators and that do not involve direct classroom research.
A 2011 article in Educause [7] makes the distinction between the data that is collected in a classroom and the data that administrators have access to, and introduces distinct terms describing the two types of analysis: learning versus academic analytics. “Academic analytics reflects the role of data analysis at an institutional level, whereas learning analytics centers on the learning process.” [7] This distinction is important because different groups engage in the data collection, analysis, and development of actionable knowledge. Academic analytics is at the institutional level and thus the purview of administrators, whereas learning analytics is the purview of individual faculty. Learning and academic analytics work best in tandem: Knowledge gained from learning analytics can validate the variables identified through academic analytics. Knowledge gained from academic analytics can lead to testable hypotheses in the classroom and thus contribute to learning analytics research. The article makes the case for the value of analytics in higher education, draws parallels to personalized medicine, but also points to some pitfalls.
The University of Minnesota, like any other institution, collects data on hundreds of variables on students. Some variables are pre-enrollment, such as ACT scores, others are collected while the student is enrolled, such as GPA. Most of the data reside in transactional databases that are optimized for quickly updating records. Downloading large amounts of data for analysis requires a Data Warehouse. To make data available in a more user-friendly way, the University prepares reports for information that is frequently used, such as enrollment or tuition reports.
A more sophisticated approach to data analysis, however, could go well beyond reports. The biomedical field has dealt with the data deluge by developing bioinformatics methodologies that draw from multiple disciplines, including data mining, visualization, and machine learning. These tools take high-dimensional data and reveal complex relationships or lead to predictive models. These same methodologies can help institutions to turn educational data into actionable knowledge that is accessible across groups, ranging from administrators who need to decide on where to invest resources, to advisers who can help students select a course of study appropriate to the preparation of the student, to faculty who can use the information to improve student learning, and to students who can take control of their own learning.
The following example illustrates the type of information that can be extracted from applying bioinformatics tools to student data. We look at a heat map that is similar to the heat map I saw in the Journal Club presentation. But this time, the heat map is based on student data. It clusters a group of students along 22 indicators, which range from pre-college variables, such as ACT or high school rank, to variables that indicate progress during the first four years of study, such as GPA or status of enrollment (Figure 2). Each row is one of 22 variables, and each column is a student. The colors range from red, indicating high performance, to green, indicating low performance. The heat map reveals clusters where all indicators are high, but also clusters where all indicators are low. There are groups of students who performed well despite low incoming indicators, and vice versa.
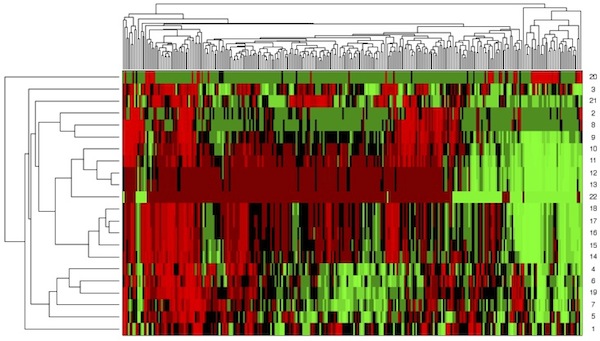
Figure 2: Heat map of student performance
Clustering students as in Figure 2 can help identify students at risk and students who are likely to perform well above average. We may devise different strategies for each of these groups to optimize their student experience. Since these tools are designed to work with smaller samples sizes as well, separate models can be built for each college or coordinate campus to recognize differences among them. While for some colleges the ACT score may be a predictor of student success, for another college the credits completed prior to entering the college may turn out to be a more important indicator. Furthermore, predictive models can be built that make predictions for individual students, leading to individualized education.
The success of translating actionable knowledge into individualized interventions relies not only on being able to identify the group of students for whom an intervention may be particularly effective but also on our ability to communicate intervention effectively to the group. This can be accomplished by developing advising tools that recommend actions to individual students in real time. For instance, when a student registers for courses, the advising tool may warn a student that s/he may have a high probability of not succeeding in a course based on the success rate of students with a similar profile, and perhaps recommend a better path. The same tool can also work to encourage students to take a more challenging course of study if the system finds that students with a similar profile did well with a more challenging set of courses. While the tools will not replace face-to-face advising, they can give students instant feedback and encourage students to take control of their own education by being able to run scenarios that return success probabilities. Similarly, these tools can help advisers identify students early on who need additional help and tailor their advising to the student based on a rich data set. The advising tools will continue to improve with the accumulation of student data over time and as we learn more about which factors are important for the diverse groups on campus.
A Vision for Academic Analytics at the University of Minnesota
Academic analytics has received attention in the past at the University of Minnesota. A 2009 President’s Emerging Leaders (PEL) Program project on Academic Analytics [8] listed five key themes, among them the unique needs of colleges and coordinate campuses, the need for better analytical tools, and the need to increase the analytic capabilities within the University. The report built on other reports that addressed similar needs, listed challenges, and made recommendations. With the continued need for evidence-based decision making, the time seems ripe to implement a robust academic analytics framework at the University of Minnesota.
The PEL report took a very broad approach to academic analytics that encompasses all business processes within the University. While analytics can aid decisions across the University, the vision here is focused more narrowly on academics. We define academic analytics as the use of statistical and data mining tools to academic data sets with the goal of revealing trends and patterns, running scenarios, and building predictive models to improve student success through evidence-based interventions. It is important to realize that this vision goes well beyond the type of analysis that is currently carried out in the Office of Institutional Research (OIR). It will not replace this type of analysis, but rather complement it to lead to individualized education.
A small investment in additional analytical capabilities to develop individualized education could allow the University to develop a sophisticated tool kit that would produce reports and predictive models that are tailored to each college and coordinate campus, thus turning data into actionable knowledge at a local level, recognizing that not all interventions are equally effective across colleges and coordinate campuses. In addition to reports and predictive models, this new approach to analyzing student data would lead to the development of tools for advisers and students to personalize the educational experience that goes beyond what is currently available through Academic Support Resources (ASR) Pillar Applications, such as APAS, thus realizing the vision of individualized education. A central resource would be more cost-effective than developing the skill set locally since the same tools can be applied to different colleges even if the actionable knowledge differs from college to college. It would also result in a consistent approach to interpreting the data and sharing information across colleges. A close collaboration between colleges and coordinate campuses and the analytics group would provide the necessary feedback to respond to the needs of individual colleges, and result in software applications that would allow different stakeholders to explore the data.
References
[1] Inauguration Speech (Accessed April 29, 2012):
http://r.umn.edu/prod/groups/umr/@pub/@umr/documents/content/umr_content_179695.pdf
[2] Policy Changes Adopted on Second Reading: Criteria for Accreditation. Higher Learning Commission. (Accessed, May 12, 2012 on http://www.ncahlc.org/Policy/commission-policies.html: https://content.springcm.com/content/DownloadDocuments.ashx?Selection=Document%2Cd15829b8-1d6d-e111-b379-0025b3af184e%3B&accountId=5968)
[3] Cowart, 1987. What Works in Student Retention in State Colleges and Universities. (Accessed April 28, 2012: http://www.act.org/research/policymakers/pdf/droptables/AllInstitutions.pdf)
[4] Habley and McClanahan, 2004. What Works in Student Retention. (Accessed April 28, 2012: http://www.act.org/research/policymakers/pdf/droptables/AllInstitutions.pdf)
[5] What Works in Student Retention. Fourth National Survey. Public Four-Year Colleges and Universities Report. ACT 2010. (Accessed on April 28, 2012: http://www.act.org/research/policymakers/pdf/droptables/PublicFour-YrColleges.pdf)
[6] Dick, L., A. Franqueira, and J. Oeltjen. 2012. iSEAL: An Integrated Curriculum in Its Natural Habitat. (Same issue)
[7] Long, P. and G. Siemens. 2007. Penetrating the Fog of Analytics in Learning and Education. Educause Review. September/October 2011, pp.31-40.
[8] http://www1.umn.edu/ohr/prod/groups/ohr/@pub/@ohr/documents/asset/ohr_asset_128528.pdf (accessed on May 12, 2012)

